medical-text-simplification
Using LLMs to Improve Medical Text Simplification Accessibility and Accuracy - Part 1
·14 min read
An overview of how I improved state-of-the-art medical text simplification using LLMs.
medical-text-simplification
·14 min read
An overview of how I improved state-of-the-art medical text simplification using LLMs.
Medical information can be hard to understand and feel overwhelming because of its dense technical language. Simplifying it could help make important medical insights accessible to a much wider audience as soon as they're available.
In this blog post, I'll cover the main methods and pipelines I developed to solve this problem using LLMs, and how they work. I'll spare the full technical details, as it won't fit in the a bitesize style blog. Overall this post is meant to be a preview, and my full disertation will remain private.
This is the first part of coverage on my dissertation, which will focus on approaching text simplification in a programmatic and formal way - using a set of simplification discrete operations/edits. The next part will focus on how LLMs can be treated as agents to edit text in a more natural and conversational way, as well as tackling factual consistency issues.
There's a growing need for medical information that's both easy to understand and reliable.
The most important reason to automate this process is to save medical professionals time and effort, resulting in faster releases of novel knowledge from new medical research.
💡 Solution: Use LLMs to automatically simplify medical text, ensuring facts are preserved.
There's also a lot of data on the poor availability of high quality medical information:
One of the most valuable datasets for this task is the Cochrane Dataset, which contains 4,458 entries of systematic reviews in healthcare. Each entry includes:
Both the original and simplified texts contain multiple sentences. Therefore this problem is formally named paragraph-level text simplification instead of sentence-level. More on the impliications of this later.
Here is an example entry from the dataset:
Medical Abstract - complex
A review of 24 RCTs with 2147 participants found no significant benefit of dopamine agonists over placebo for dropout, abstinence, dependence severity, or adverse events. Two small studies suggested antidepressants may outperform amantadine for abstinence, but evidence quality was low. Overall, current RCT data do not support dopamine agonists for cocaine misuse treatment.
Plain Language Summary - simplified
We reviewed 24 studies with 2147 adults addicted to cocaine and found no benefit of dopamine agonists over placebo for quitting, staying in treatment, or side effects. Antidepressants may work better than amantadine, but the evidence is weak. Overall, there'’'s no good evidence to support using dopamine agonists to treat cocaine addiction.
I will show you the different methods I developed for achieving a high quality simplifications with LLMs, ensuring medical correctness.
The goal is to build an automated system that can:
Current solutions rely on smaller, less capable pre-trained language models like BERT. These models have some major limitations:
Another big issue is factual consistency. These models can:
| Model | What It Does |
|---|---|
| BART-UL | A transformer model that uses a special loss function to avoid jargon (Devaraj et al., 2022). |
| TESLEA | Uses reinforcement learning to balance relevance, readability, and simplicity (Phatak et al., 2022). |
| NapSS | First summarizes the text, then simplifies it using a transformer model (Lu et al., 2023). |
| UL+Decoder | Improves on unlikelihood loss and ranks sentences by readability using beam search (Flores et al., 2023). |
The primary metric for evaluating simplification quality is SARI, which measures how well the generated simplified text performs compared to the expert's simplified text:
We also use more naive metrics, to paint a more complete picture. Here is a summary.
LLMs will allow a more robust, more performant, and widely applicably solution that won't become redundant due to new model architectures. As new LLMs are released, the model's comprehension and intelligence automatically gets better, assuming the prompting strategies are still compatible.
transformers.Prompting is how we communicate with LLMs to guide their behavior. Here are the foundational strategies that improve the quality and control of simplified outputs.
These techniques are applied throughout my entire project.
In zero-shot prompting, we give the model a task without providing any examples. It's simple, but can be hit-or-miss depending on how clear the instruction is.
Simplify the following paragraph for a general audience:
"Dopamine agonists showed no significant benefit compared to placebo in reducing cocaine dependence."
Few-shot prompting improves output by including a few examples of what we expect. It helps the model learn the format and style from the prompt itself.
Simplify the following like the examples:
Original: "This meta-analysis included 24 randomized controlled trials."
Simplified: "We looked at 24 reliable studies."Original: "Adverse events were moderate in severity."
Simplified: "Side effects were not too serious."Now simplify:
"Dopamine agonists showed no significant benefit compared to placebo in reducing cocaine dependence."
Chain-of-thought prompting encourages the model to reason through its steps before producing the final output. This is especially useful for preserving meaning and factual accuracy.
Let's think through the simplification:
- Identify complex terms: "dopamine agonists", "placebo", "cocaine dependence".
- Replace them with simpler words.
- Rewrite the sentence clearly.
Final simplified version:
"Drugs meant to treat addiction didn’t help people with cocaine problems more than fake pills."
You can also improve results by clearly setting the model's role or audience:
You are a medical writer explaining research to the general public. Rewrite the paragraph in plain language, keeping it accurate and clear.
Being specific about what you want and who the model should act as helps produce more relevant and reliable outputs.
While LLMs are capable of generating simplified text end-to-end, they often do so without understanding the specific operations that underlie high-quality simplification. To emulate expert behavior in a controlled and interpretable way, it's useful to break simplification down into fine-grained operations - both at the sentence and document-level.
These focus on rewriting a sentence in isolation, and represents the most popular subfield of text simplification. This using techniques such as:
These operations help, but they don't address larger issues like repetition, flow, or overall readability.
This approach considers the entire paragraph or passage, using higher-level operations to improve cohesion and structure.
The main motivation of these operations is that sentence-level operations do not simplify the broader, overall content, since they are isolated and unaware of the surrounding sentence context.
In the Cochrane dataset, the number of sentences in the PLS often is larger or smaller than the original complex text. Sentence-level operations cannot support these edits.
These broader changes are essential for making medical reviews easier to read in context - not just sentence by sentence.
This informed the design of my first pipeline, Plan-Execute which selects an action to execute, Few-shot prompting. The chosen action is outputted as a JSON object, which automatically selects a single operation - document/sentence level. These are each implemented as few-shot prompts too.
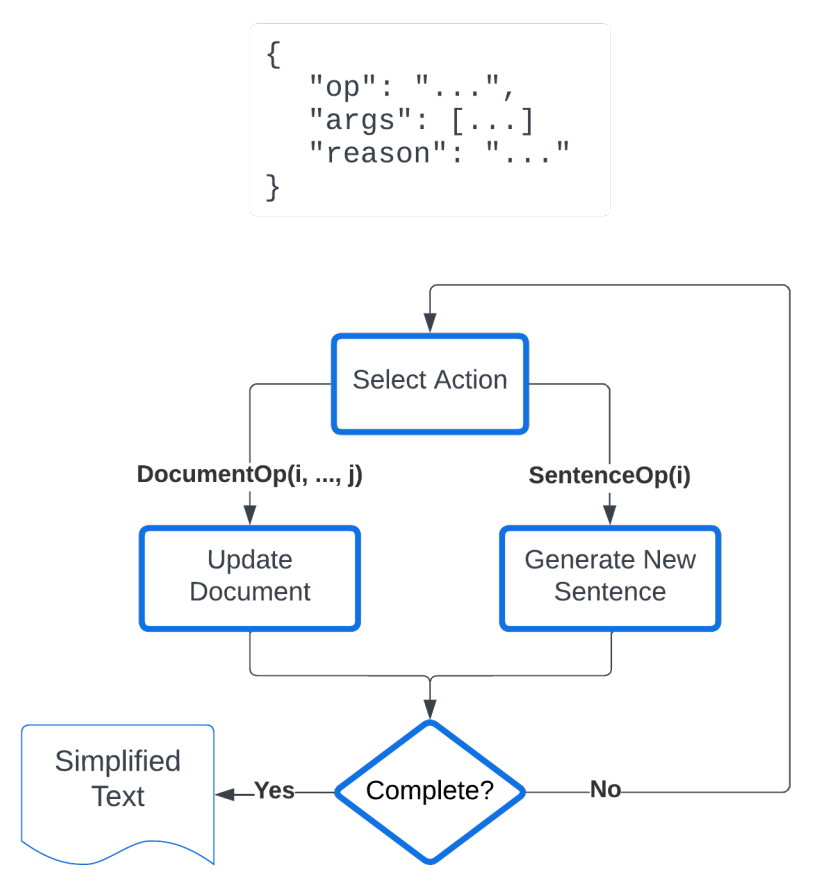
The main issue is with action selection and its efficiency - the model gets overwhelmed and can't properly decide. Therefore we should make the process more modular and break it down further.
I begun by analysing the type of sentences found in each abstract by prompting an LLM to classify each sentence with zero-shot prompting.
| Category | Description |
|---|---|
| Introductory | Defines the study, number of trials, participant demographic, location, and time-frame |
| Results | Presents or explains collected data and observed outcomes of the study |
| Recommendation | Suggestions aimed at patients |
| Limitation | Constraints and factors that affected research |
| Conclusion | Summary of the main outcomes |
| Other | Used when an LLM is uncertain of classification |
This analysis revealed the distribution of sentences by topic, allowing the LLM to become more aware of the content it should keep or remove. For example, "Results" and "Recommendations" are the most important sentences for a casual reader to comprehend. Sentences of topics "Limitation", "Other" will be much less relevant. The LLM can implicitly focus on more important sentences once it has been explicitly labelled in this way.
We'll focus on how we can extract the most important sentences to keep in the simplified text, applying our knowledge from document-level simplification. This approach, using LLMs, offers a more interpretable and flexible filtering process, compared to existing methods.
Classify Then Filter PipelineThis method applies our classification prompt, and adds an additional step to select k sentences using Chain-of-thought prompting to reason about it.

Generate and Match Key Points PipelineThis method applies inversed logic to the previous classification method. We want to match sentences to a list of important key points, to prune irrelevant detail.
To focus abstracts around their core themes, we first generate a set of concise key points summarizing the full content. These are created using few-shot prompts to guide style and brevity. We then filter out non-essential points with Chain-of-Thought (CoT) prompting, requiring justification for each removal.
Next, each sentence from the abstract is matched to this refined list using a zero-shot prompt. If a sentence cannot be linked to any key point, it is excluded. This selective filtering helps retain only the most relevant content, ensuring the final output reflects the abstract's central ideas.
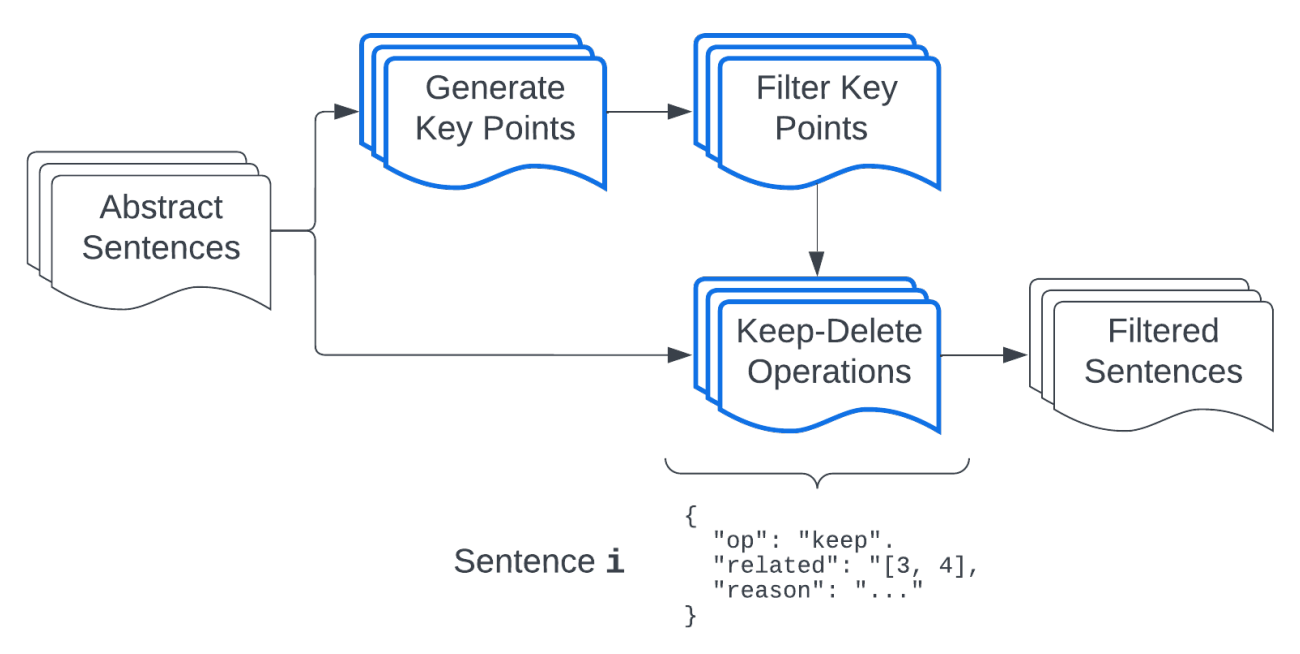
Most simplification studies rely on zero- or few-shot prompting. I explored reasoning-enhanced prompting techniques — Chain-of-Thought (CoT) and ReAct — to improve sentence simplification by interleaving reasoning with operations like replacement, compression, etc.
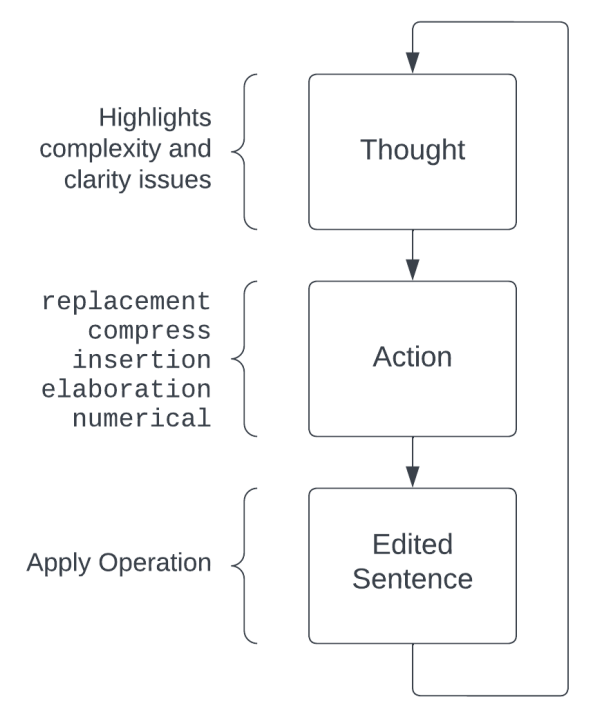
ReSimplify - Reasoning-Guided SimplificationIn this sentence-level pipeline, I applied the ReAct prompt technique to text simplification. But what is ReAct?
It is a technique to prompt a LLM to act in an interleaved fashion, combining reasoning steps with actions, such as executing tools (e.g. a Calculator or search query) or interacting with an API. In ReSimplify, the actions are our sentence-level operations, and reasoning steps allow the model to present a more guided and controlled simplification process, that more directly engages with the complexity issues of the text.
In short:
Word Replacement, Compress sentence, Insert words, Elaborate phrase, Rewrite Numerical Jargon.
Lets look at an example.
Complex Sentence:
The meta-analysis demonstrated that treatment for CIN did not adversely affect the chances of conception.
Thought 1: Begin by simplifying complex non-medical terms, clarify sentence structure
Action 1: Replacement
Tag:
The meta-analysis <sub>demonstrated that treatment for</sub> CIN <sub>did not adversely affect</sub> the chances of <sub>conception</sub>.
Replacement:
The meta-analysis showed that treating CIN didn’t harm the chances of getting pregnant.
Thought 2: Expand abbreviations.
Action 2: Insertion
Tag:
The meta-analysis showed that treating </ins> CIN didn’t harm the chances of getting pregnant.
Insertion:
The meta-analysis showed that treating cervical intraepithelial neoplasia (CIN) didn’t harm the chances of getting pregnant.
Thought 3: Clarify non-essential medical jargon.
Action 3: Replacement
Tag:
The <sub>meta-analysis</sub> showed that treating cervical intraepithelial neoplasia (CIN) didn’t harm the chances of getting pregnant.
Replacement:
The research review showed that treating cervical intraepithelial neoplasia (CIN) didn’t harm the chances of getting pregnant.
Thought 4: The sentence does not have any remaining complexity issues.
Final Simplified Sentence:
The research review showed that treating cervical intraepithelial neoplasia (CIN) didn’t harm the chances of getting pregnant.
A much more controlled method compared to Few-shot and especially zero-shot.
The prompt enables an iterative process to be executed by the LLM, allowing a multi-stage simplification to be completed in one LLM inference step.
My evaluation results concluded that ReSimplify outperforms other prompting strategies and competes with state-of-the-art systems - specifically it achieved a high SARI score of 40.02 on the Cochrane dataset. This shows the effectiveness of reasoning-guided sentence simplification with LLMs, and its flexibility. It can easily be applied to other technical domains.
The ReSimplify method can be applied as a post-processing step once we have applied our document-level operations. I followed this idea in my "Filter-Join-Split-Simplify" pipeline.
This method is inspired by Cripwell et al. (2023), who view document-level simplification as a two-step process:
We adapt and extend that approach into the following pipeline named Filter-Join-Split-Simplify:
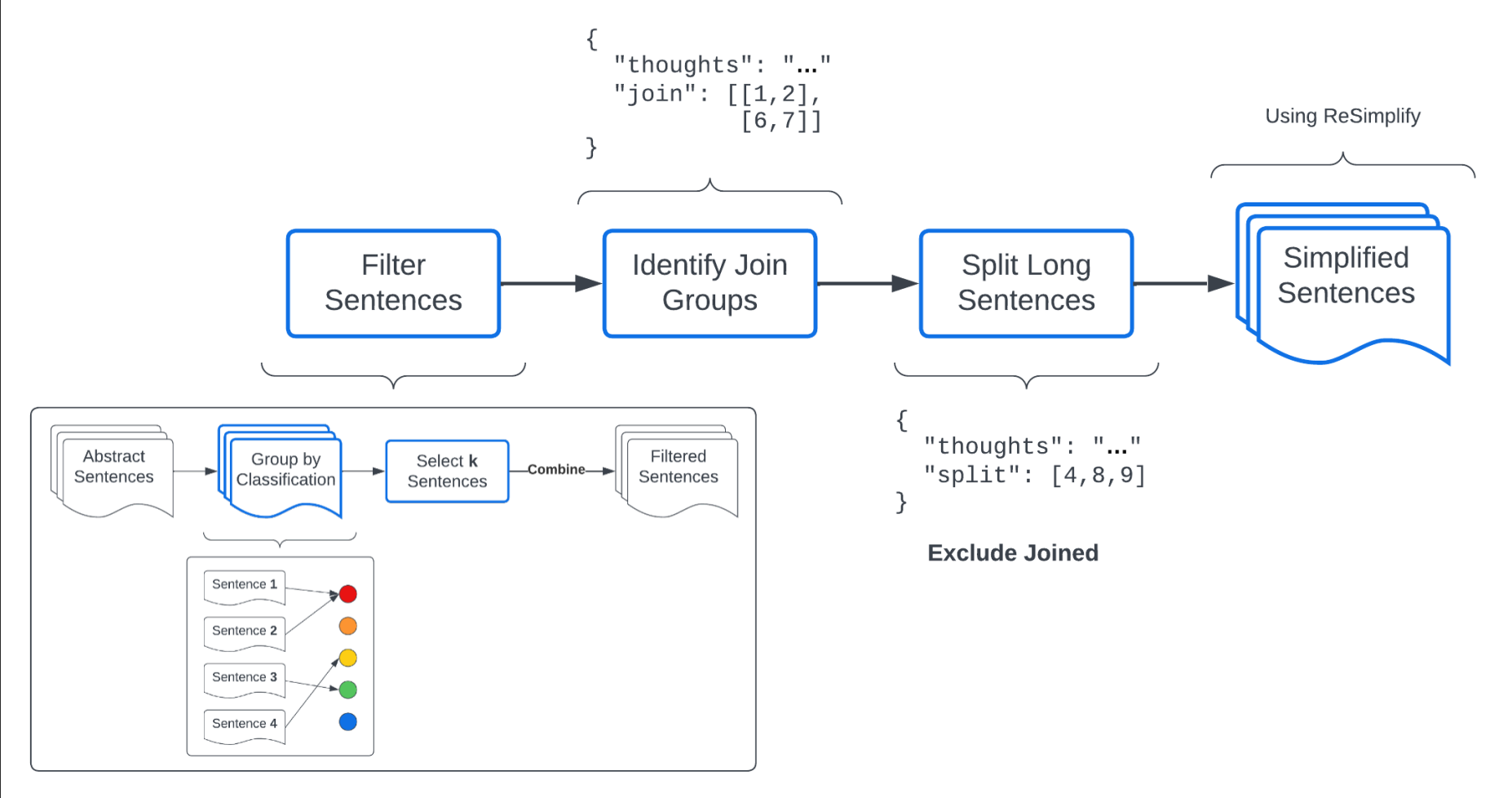
This method proved effective at removing unimportant information efficiently, and grouping sentences together in a concise way.
This post covered the motivation, approach, and implementation of using LLMs to medical text simplification. Specifically we used a formalized and programmatic approach that relied on continuously applying discrete operations to the text.
In Part 2, I'll dive into how LLMs can be reframed as agents and used in multi-agent text simplification pipelines, in order to achieve a more natural simplification process. I'll also discuss methods for tackling factual consistency issues.